Duplicate Indices Map
You are processing a batch of records represented by integers. Some records appear more than once, and the review team needs a quick way to spot where each repeated record occurs. Your task is to build a collection of index groups: for every value that occurs more than once, gather all of its indices as a list. Return a list of these index lists, each representing a duplicated value.
Consider each index as a position where the repeated value makes an appearance. By grouping these positions, you reveal the hidden patterns within data entry streams or similar logs. Only values that appear at least twice qualify, so if every entry is unique, the output should be empty. The order of the outer list does not matter, but each inner list should follow the natural index order in which the value appears.
Think of this as cataloging where repeated stamps show up in a collectors album. If a stamp design is seen only once, its index is not recorded. But if the same design is spotted multiple times, each location gets noted together in a single group.
Example 1:
Input: nums = [1,2,3,1,2,1]
Output: [[0,3,5],[1,4]]
Explanation: Value 1 appears at indices 0, 3, 5; value 2 appears at indices 1, 4.
Example 2:
Input: nums = [7,7,7]
Output: [[0,1,2]]
Explanation: Value 7 repeats across all positions.
Example 3:
Input: nums = [4,5,6]
Output: []
Explanation: No duplicates exist.
Algorithm Flow
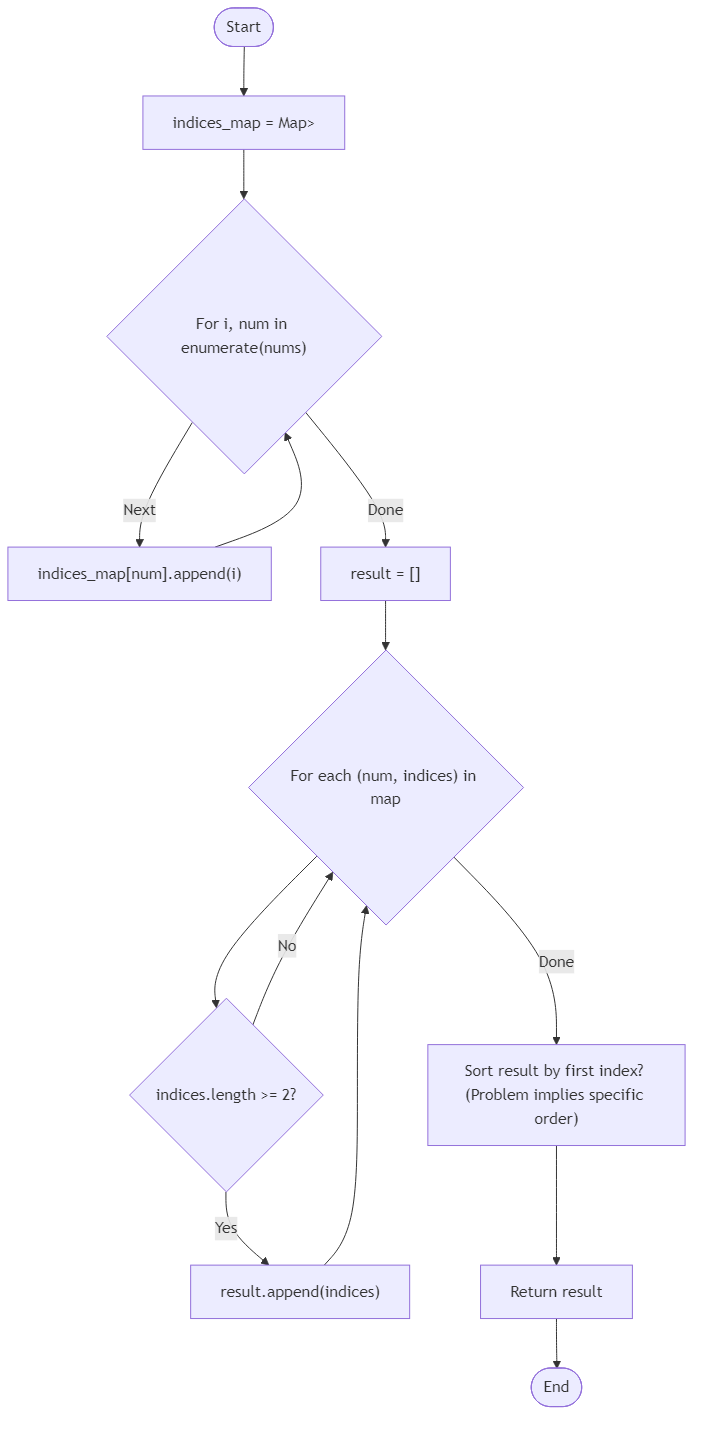
Best Answers
import java.util.*;
class Solution {
public Map<Integer, List<Integer>> duplicate_indices_map(int[] nums) {
Map<Integer, List<Integer>> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
map.computeIfAbsent(nums[i], k -> new ArrayList<>()).add(i);
}
Map<Integer, List<Integer>> result = new HashMap<>();
for (Map.Entry<Integer, List<Integer>> entry : map.entrySet()) {
if (entry.getValue().size() > 1) {
result.put(entry.getKey(), entry.getValue());
}
}
return result;
}
}Related Hash Table Problems
No related problems found
Comments (0)
Join the Discussion
Share your thoughts, ask questions, or help others with this problem.